Nov 13, 2020 - Newspaper articles on my wall
(This has been sitting in my drafts folder for months; I need to just post!)
As a teenager in the early/mid 2000s, I cut out my favorite articles from print publications (Plain Dealer - the daily newspaper in Cleveland, or the Free Times, the Scene (the local alt. weeklies), or the New York Times - I had a subscription when I was home from college); I would then glue them onto poster board and then hang them up on my bedroom wall using sticky tack or push pins.
I don’t know where I got the idea for this; I don’t claim to be the original.
While cleaning, I found some of these and decided to document them before I threw them out.








(As a part of my effort to document my life on my blog instead of just on twitter, I’ve posted this here.)
Oct 16, 2019 - Recently
(Reminder to myself, this was originally drafted in April and to use this more often to share small snippets of information..)
I second guess myself if I don’t do enough to remove our president (if it’s not clear, generally, I do NOT support his policies). I try to let my actions speak for myself but I wonder whether its enough; I know that those who are privildged (and also often have power (financial, influence)) to not have to deal with the ramifactions are generally quickly turned off and that the effect of my sharing it on social media is probably minimal. I keep that in mind by trying to act locally.
While in college 10-15 years ago (damn, it has been that long) I realized that the fate of our country for most of its residents wasn’t going to be as good as it once was; and unfortunately that’s been the case. Financially, my partner and I are a little bit better off than my parents were thanks to education, priviledge, and a bit of luck (especially with our health); but there’s more precarity in our future than in the past due to our current administration and with the increasing costs of health care.
I’ve been more intentional in backing up my photos, documents, and videos on a using a combination of rclone and backblaze b2.
There’s a really sharp learning curve (knowing the basics of bash, cron, unix are a requirement for these tools) but the value is really good (per GB); the customization and automation are great.
While looking at past photos, I realized that I haven’t taken that many photos of myself or friends actually.
I’ve pared down even more of what I’ve shared on social media.
I was cognisant of this before (this isn’t the result of anything in particular and I don’t think there’s anything out there that I’d deeply regret) but more so of even less trust that my information may be used against me (denial of health care coverage)
I’ve been contributing to OpenStreetmap for nearly 9 years. It’s how I fell in love with maps; gave me multiple career options, opportunities to work in Haiti and Sengal, forge friendships and acquatinences across the world that continue today, I’ve given a couple dozen presentations or some aspect of it. I wouldn’t be where I am today without it. It has changed my routine; encourages me to be much more observant of how the environment is built, notice the little businesses with signage that would otherwise be forgotten and fade in the landscape.
It’s my biggest hobby (and relatively affordable too ;)), probably 3-4 hours a week.
I’ve lost a little luster for it over the past year or so. I still edit nearly every day, but the quantity of edits and my overall involvement has decreased.
I second guess more often while I’m editing: how often is this data in a way that’s positive for the world? I had thought about this many times before but this just wears on me more.
Will there be more usage of it besides just routing for private ride-sharing companies or real estate analysis?
The local transit authority began to use OSM on their route maps; so that’s actually a great positive.
In OSM, there’s less focus on how users can extract or use its data to make simple maps without having to know HTML or geojson or perform some basic spatial queries (e.g. where are coffee shops or child care facilities that are within 1 mile of me?). The OpenStreetMap community focuses more on how to get data into OSM but not enough on how to get the data out of it (unless you have very )
After spending about 8 years across different continents and areas; you see some of the weaknesses of the tagging system; (to be fair, I think any crowd-sourced system would have probably had these issues).
Looking back, I’m a bit surprised that editing hasn’t taken off like it has for wikipedia; the killer app for openstreetmap (to drive individuals or companies) to contribute for use never came and I think that window of opportunity - for OSM to become the defacto standard in America has passed.
There was a period, I think in the late 00s and perhaps early 2010s when OpenStreetMap and its crowdsource model - manaully drawing features through drawing of aerial imagery and gps traces was the most efficient; and google maps didn’t quite have its strong market share.
Since then, open data sets from municipalities have become more plentiful, machine learning for drawing features have greatly improved. Google uses the crowdsourced data from all of the captchas we fill out to identify addresses and features that they’ve collected from their Street View vehicles.
For a bit, I thought MapBox may have been that company whose products would incentivize people to contribute to OSM and increase its usage of OSM to unforeseen levels of use but it looks like they’ve focused a bit more gathering data through sensors and focusing on automobile navigation.
I sometimes wonder if another entity in a few years will usurp OpenStreetMap as a widely-used defacto source of crowdsourced, global geographic data. OSM largely hasn’t tackled the representation of 3D features; still represents more features as lines instead of areas (no doubt, representing everything as an area would be a lot of work for mappers at this point).
There’s a lot more to share; I also need to make this process of updating this and then uploading it to the website a little easier.
I’m also over markdown, the language that this is written; I’d rather go to just pure html and css again.
Mar 5, 2019 - Digitizing Cleveland's Historic Annexations
I created a digitized dataset of Cleveland’s historical land annexations and it didn’t exist before. Thanks to this data set, I was able to make this time-lapse map displaying the growth of Cleveland’s historic annexations and additional research can more easily be done.
More below on what I learned, why I did it, what else can be done with this new data set.
If you just want the data set, download the annexation boundaries at https://github.com/skorasaurus/cleboundaries
Why I did this:
As a part of my day job as a web developer at the local library, I met with Marty, the City of Cleveland Archivist, about an unrelated issue with the Cleveland Public Library website. He graciously gave me a tour of the City Archives across from the Justice Center in Downtown Cleveland. He had large copy (2 x 3 foot) of an annexation map from 1968 on the wall and often referenced it for city employees. I’ve been a fan of maps and he mentioned in passing that since that map’s publishing, there have been additional annexations but no map has been made since then*** and no one had the time or resources to do it.
(Just in early 2019, I found an annexation map on made in wikipedia made around 2010 by Paul J Meissner but I haven’t been able to contact him or obtain it in a higher resolution. Additionally, that map appears to use Google which goes against Google’s Terms and Conditions and is not on very firm ground to be legally shared.
{kind=link}
Aloud to Marty, “I could make you a newer print map with those annexations”, I offered to make one (I’m still working on it).
To make a new print map, you would need the annexation boundaries data set first.
That data set didn’t exist, until now.
Answering historical questions that couldn't be answered before:
Creating this data set by creating the digital boundaries doesn’t solve any civic technology problems by itself; but like other open data sets, it can, with additional effort, be used in with other data sets to answer questions like:
- How much of Cleveland's population growth in the 19th and 20th century can be attributed by annexating other places?
- Did Cleveland's population grow at the same proportion in the 20th century as its size?
- Did proposed or implemented annexations had any influence on development patterns or migration patterns for residents in the 19th and 20th century?
I’m also casually interested in how past city decisions influence our present day. How would Cleveland and Northeast Ohio would be different if certain areas were never annexed or annexed at a later date (or certain places that were once considered for annexation, like East Cleveland and Lakewood, were annexed).
In the process of creating these boundaries, a scholar had contacted the Cleveland Public Library with a research question seeking the historical Cleveland boundaries (!) (I found out through my day job) and I was able to provide him with some of my data.
These boundaries can also be used as the basis for a new printed map of Cleveland annexations.
A look at historic open data
Through my years in open data advocacy and mapmaking, I hadn’t known much about available past, open accessible historic geospatial data. Historic geo data generally wasn’t included in municipal open data portals.
Before this project, I hadn’t known of any historical annexation boundaries to exist but Karl Phillips has been doing prolific work on digitizing historic annexation boundaries and had been putting his annexation boundaries up on mapstory (a neat site in its own right) although you won’t find them there right now; mapstory redesigned their site and deleted some of the existing work. Karl told me he’s planning on reuploading them to mapstory. Reach out to him at Phillips AT MapStory dot org.
In addition, this project may be used to get myself and others more attention to the question of who should store historic geospatial data (and how).
I suggest that the overlooked the public library may be appropropriate:
I discuss in an earlier post why public libraries can be great places to host and curate civic data (domain expertise of subjects, community understanding/trust as a place to get knowledge in a way that doesn’t feel as stuffy or intimidating as an academic library would, and a 3rd party source [generally] outside of direct municipal government control).
Although Mapstory likely had good reasoning why they deleted previously uploaded data sets and had good intentions in the first place, it’s an example of caution to rely on 3rd party sources for historic information. In case where others like entities like mapstory may temporarily data that was behind the map (although I’m sure they had good intentions and reasoning why they had to delete the data sets). (I did contact them about 2 weeks ago asking to learn more but did not receive a response.)
I’ve talked with some co-workers on how that our data set can be something that we can be the steward at the library; we haven’t stored any geospatial data just yet, and to my knowledge, no or very few public libraries do yet (Maybe I’m running in the wrong circles; I’d like to know where).
That means we have to set up the resources to host it and and our current digital system doesn’t store geographic data and I’d also have to figure out how other binary data sources should be stored. This is not an insignificant question. Something I’m looking forward to figuring out and hear you opinions.
Many public libraries may not have the infrastructure or technical knowledge to do this; so maybe this is something that occurs in collaboration across multiple libraries, ala DPLA.
The geographic data set is currently available as Shapefiles and geojson at my github repository of Cleveland Boundaries, cleboundaries where the metadata and additional notes are also located to understand the data.
The data set as of this writing is not yet complete. There are several annexations from the 2nd half of the 20th century that need to be added, especially around the Cleveland International Airport.
I’d like to have a consistent way of determining annexations’ “start dates”. Should it be when the annexation was passed in legislation or when it was effective ‘on the street’? When acknowledged/recorded by the state or county? As I far as I know, all of these dates vary.
How did I do this?
The process of georectification isn’t easy, so I think there’s some value in writing this out. I’ll breifly outline how I created these polygons.
Maps that are images (not ‘web maps’ like google maps) or paper maps scanned into a computer cannot be overlaid a web map with georectification.
When you first scan a paper map into a computer, there’s no information within the image that tells the computer “this portion of the image” is in Cleveland, Ohio (or any another particular place).
Very broadly, this absence of context is similar to when you scan a paper document, you cannot immediately select the text on it. You can visually see with your eyes what the words say; but computer software only knows that there are black and white shapes there; computer software does not known those shapes also represent characters of a language.
(These are completely different processes but very abstractly, the same process. )
Transforming the image of a map (in this case, the annexation map from 1968) and aligning to specific locations by a coordinate system is known as georectification (this a term very often interchanged with ‘georeferencing’; the terms are confusing (ESRI’s definition of georectification)
Lincoln Mullen does a great job of explaining the overall process of georectification.
When I first started the project, I planned to create the geographic shapes by first georectiying what I dubbed the 1968 map, a hand-drawn map by the City Engineering and Construction Dept. that is the most recently published version of a map with the boundaries. Then, I would create the shapes by tracing over the georectified map.
I first tried georeferencing the 1968 map on mapwarper.net; a great free, open-source tool (although he deserves some $ for this, but I digress); and used OpenStreetMap as the reference map.
After making over 20 reference points with the 1968 map in mapwarper.net, I found that many places in the 1968 georeferenced map it still didn’t match up well with my reference map; In many places, I was getting only about 30-40 meter accuracy.
As shown in the image below, the black lines representing streets from the 1968 map; with aerial imagery from state of Ohio imagery (circa 2015) as the referenced map.

I came to the conclusion that the 1968 map wasn’t drawn very consistently. It was hand-drawn somewhat poorly and that I could not merely trace over the georeferenced 1968 map. I couldn’t rely primarily rely on that. At this point, I also began relying primarily on TIGER and the state of Ohio’s aerial imagery, to eliminate any copyright restrictions (which would have occurred if I would continue using OpenStreetMap) on my data set.
Instead, I had to use the 1968 map and the Volkmann map as sort of a guide: Look at a particular polygon in the 1968 map and volkmann map by identifying them on one of the maps(thinking my mind, “oh, western border of this polygon is a house-worth’s east of east 156th”, then open up the TIGER/State of Ohio imagery and draw it in the same location.
So, on and off, over a few months on idle Saturdays, I drew the polygons. At one point, I stopped because I wasn’t sure which dates to use in the source data as ‘actual date of when annexations were implemented’ and that discouraged me for a few months.
Not until a few months in the process, I realized that I could also use the historic plat maps from Sanborn and Hopkins some which are digitally available (but not georeferenced) from the Cleveland Public Library’s Digital Map Collection and The Library of Congress.
The Sanborn and Hopkins maps represent property-level maps of historic Cleveland from the early 20th century and late 19th century. They also include the municipal boundaries on the map.
Below is an image 4, from vol 4 of the 1896 Sanborn, courtesy of the Library of Congress
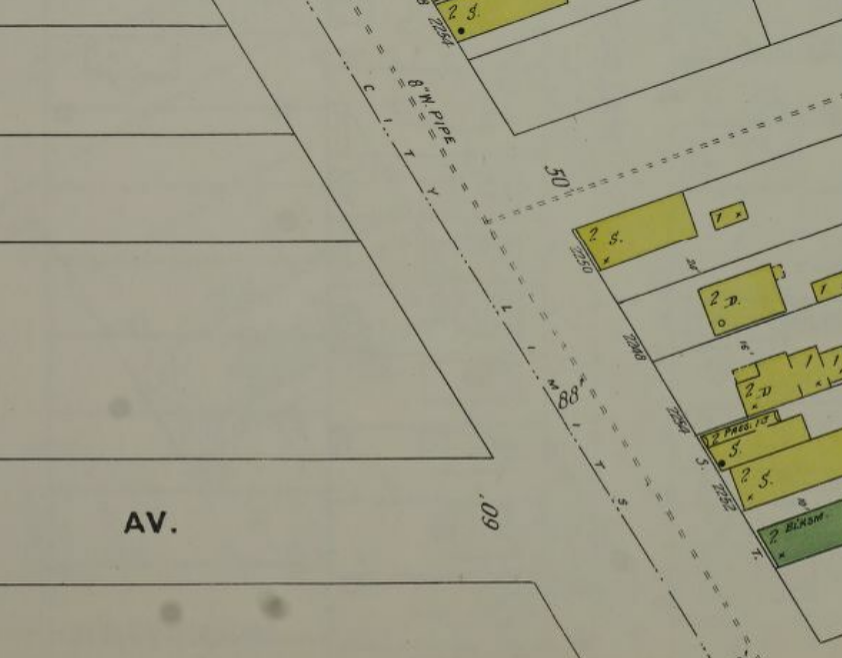
The Hopkins and Saborns provided a tremendous amount of detail that was not available in the 1968 or Volkmann maps and I began using them as my primary references.
Going forward as I refine the maps the great detail of the Sanborn and Hopkins maps along with manual verification of the original City Council legislation (the actual true authority) will likely be the best to determine the accuracy and details of the boundaries.