Apr 10, 2018 - Georeferencing the past
I’ve been learning about georeferencing (what is georeferencing) maps for an upcoming project at work to display a print map (24 x 36 inch) where the library provided services circa 1912.
My secondary goal for georefencing these maps is to provide a web map layer for users to browse historic Cleveland at a high resolution detail (i.e. at zoom level 19-20).
Before I started this, my knowledge on georeferencing wasn’t much and I didn’t know what I’d use as the base map for my project - one that would provide viewers a sense of streets, intersections, and lack of sprawl in 1912…
Here’s what I learned and what I’m still trying to figure out:
The sources of paper maps:
CPL has Sanborn maps. Produced every few years in the early 20th century, Sanborns richly detail addresses, landuse, streets, rivers, buildings, and often times, property owners, of the entire city. Sometimes the buildings usage was also noted. In addition to their utility, they are relatively asthetically pleasing. They’re also available at an extremely fine scale, a scale of 200 feet per inch.
These maps were published as a bounded book of ‘plats’/’plates’ - pages - each roughly 15 by 10 inches of an arbitrary geographic area.
CPL also have “Hopkins Maps”, made by a different company, but same physical layout and map design.
Fortunately, CPL has unbounded a few editions, digital scanned them, and uploaded them into in our digital map collection
For the city of Cleveland’s 1881 Hopkins maps, there are 40 pages; each image with borders containing extraneous information (page number, map key) and on several pages, contained areas that are also displayed on another plat.
Although the LOC will eventually be uploading historic Sanborn maps of the entire country, they have barely started the state of Ohio save for good ole’ (Monroeville).
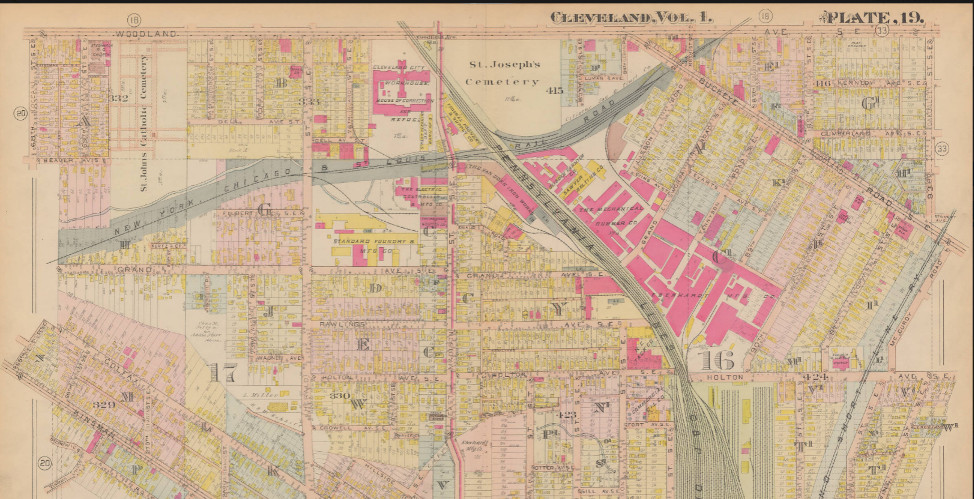
As shown in the above image, there’s extraneous information (the map scale, the north arrow, the plate number) on each page that would need to be removed or clipped out if I wanted to present them as one congruious map. The image in Cleveland Public Library’s digital gallery
If I wanted to create a contigous map, I had a fair amount of work ahead of me:
and I didn’t even know what order I should do these steps?!
So, how do I do this?!
I had multiple questions when I first started:
Do I stitch the plat(e)s together first and then georeference them? Or do I georeference first?
What tools do I use stitch them together? (stitch - creating them as if they appeared as one contiguous image)
How much accuracy should I get from them? Is 5 meter accuracy (from a reference layer) realistic? What if the original map had distortions in it in the first place?*
Would I be able to get results as accurate as than this GIF below? (Prospect Ave didn’t exist there at the old time, this is to primarily illustrate Carnegie Ave)

(after all, I wanted to create a nice digital map layer)
(In Cleveland, OSM is pretty well aligned (usually within 5 meters) with State of Ohio aerial imagery licensed in the public domain and that is pretty darn accurate [http://ogrip.oit.ohio.gov/ProjectsInitiatives/StatewideImagery.aspx]) So, I has a good reference layer.
I spent an hour or so exploring our scanned maps to determine if there were any that, together would provide enough coverage of the city of Cleveland. Some of their metadata and descriptions our digital collections were misleading; this item has the title of Plat Book of Cuyahoga County, Ohio Complete in One Volume (Hopkins, 1914) but if you carefully read the title page of this book and view a couple adjacent pages of it, you learn that it’s just 1 of 4 volumes that are needed to have complete coverage of Cuyahoga County. Unfortunately, we didn’t even have all 4 volumes of the 1914 Hopkins available; so I couldn’t use that as a resource.
I finally found a map collection that had coverage of the entire city of Cleveland: a Hopkins book of Cleveland from 1881.
So, I started out using the public mapwarper which is really neat.
I experimented by:
Uploading each image page to mapwarper.net (for now, just manually)
Applying the “mask” that would remove the extraneous areas I didn’t need to reference
georeferencing (rectifying) them
I learned that it doesn’t matter whether you georeference or apply the mask first to a map on mapwarper;
This recommendation maybe different if you’re attempting to use the mosaic feature on there.
Lou Klepner reported that Plate Spline is most effective rectifying method on mapwarper; I haven’t noticed definitively one better than the other. For the resampling method, I used cubic spline and didn’t find any noticeable speed delay compared to the nearest neighbor.
I then downloaded the geotiffs from mapwarper - now georeferenced that have the geographic projection stored within them - so they can be displayed over other modern maps.
Now I can open the geotiffs in QGIS as raster layers. They matched up pretty well although not perfect (ADD screenshot) and I printed a portion out in QGIS’ print composer. And… You couldn’t read the street names on the printed copy. I learned that these image were scanned and uploaded as 72ppi and don’t print well. Oops. Our library didn’t save the original loseless digital scans (they had since corrected this practice several years ago for other scanned maps).
So, more searching to see if we had another map set of the complete coverage of the city of Cleveland. Yes, we did! volumes one and two of the 1912 Hopkins of Cleveland.
72 PPI images are publicly available but we had 600PPI of these in private digital storage.
I asked Stephen Titchenal of railsandtrails.com - an underrated resource for rail maps of the 20th century; he’s digitized dozens of maps. He admitted he hadn’t stitched together any map as large as I was proposing but recommended photoshop and Panavue image assembler a since abandonwared windows stitcher but he hadn’t stitched together anything as large as I was proposing. Welp. Most of his maps were 300ppi and suitable.
Guides by Mauricio Giraldo Arteaga, formerly of NYPL, National Library of Scotland, and Lincoln Mullen are great introductions to the basics of georeferencing with mapwarper but they all assume that you’re only georeferencing one image at a time and not stitching them together.
So, now: My task, I ask for readers:
Given my constraints: computing power on my work and personal computers (Thinkpad T450s, HP Z240 both with ubuntu) each no more than 16gb of ram); would I be able to work on 1 giant image of all of the items stitched together? I tried gimp on ubuntu (to be fair it was a 600 PPI) and it was nearly unusable on a single image…
It wouldn’t be realistic to upload about 3gb of images to mapwarper.net…
So, readers, I’d love to hear your suggestions and thoughts.
I ask a few questions on how to proceed:
Given my two goals (a slippy web map and a print map of 24x36inch) would 300PPI be ok for both?
In which order should I complete the tasks of cropping/masking the plates, georeferencing the plates, and stitching them together to appear as one image?
After I georeference them, should CPL provide both georeferenced and non-georefenced items in our digial collection?
Tentatively, I think I’ll batch convert (with imagemagick) the images to 300PPI; then crop 1-2 plates of them in gimp (if it’s feasible from a memory standpoint), then try to georeference them in qgis.
For sharing georeferenced, I can see both sides whether to add the georeferenced ones because georeferencing is never perfect; it’s always a work in progress.
I’d appreciate your advice for my next steps and what you’ve learned if you’ve done something similar (email is skorasaurus at gmail, the left bar has my social media contacts). I’ll share what I’ve learned later.
Apr 8, 2018 - Tools on map-making at Data Days CLE
I gave a workshop/presentation on tools for map-making at Data Days CLE on Friday. One of my favorite moments was the city employee who asked me about alternatives to ARCGIS/ESRI and specifically being able to offer read access to geodatabases to other departments of data without using ESRI (hope I remember that correctly).
My slides are at http://skorasaur.us/ddc18 and below is a long list of resources, most of which I mentioned in my talk. This list is also available in my github repository for this - https://github.com/skorasaurus/ddc18
This list is by no means, comprehensive, but a starting point for tools for map-making, primarily focusing on web maps (maps that are viewable online) outside of the ESRI ecosystem.
mapschool - As brief as it is, it’s an extremely useful overview of modern maps and some theory. I don’t know of any other document on maps that is as short yet as informative.
mapmaking suites (SAAS, software as a service):
shinyapps - R-based
Quicker and simpler web map templates:
All of these simpler web map templates require a relatively minimal amount of data (not a very rigid rule, but I’d say less than a couple hundred points/features and that you don’t have a lot of properties on them). If you have more than this, you’ll need to upload them to one of the above services.
mapzap - less styling options but easier to use
mapstarter - also has print options
umap - If you want a map to share with others with some custom icons quickly and aren’t picky about the basemap; can embed as well.
data manipulation/gis in browser:
As above, these may not work (or will work very slowly) if you’re using files that have hundreds of features or are above, say 10mb, in size.
geojson.io - quickly edit and save to numerous formats; works on files < 10mb
mapshaper - relatively simple yet powerful, also has command-line based tool
dropchop - do some common GIS operations within the browser
turf.js - do some common GIS operations within the browser (javascript)
utilities for printing web maps:
portmap -
staticmapmaker.com - limited options; but usable
https://www.mapbox.com/help/static-api-playground/
geocoding:
smartstreets Not free; but does a relatively great job and has relatively easy to use interface; good if you’re on a timecrunch and/or limited skills.
Meta (a list of other lists):
awesome-spatial - great list of all types of spatial tools, many of these require knowledge in a particular programming language, comfortability with command line.
awesome-geojson - great utilities for working with geoJSON.
color-tools - all resources on colors
dataviz-tools’ list - thorough list, somewhat out of date
theory:
maptime - An informal association of meetup groups that teach geospatial concepts and maps. They have accessible tutorials. I co-organized Cleveland’s maptime from 2012-2014ish.
Advanced:
csvkit - python library and command line to manipulate CSV files
qgis - geospatial analysis, map-making, and so much more; comparable to ArcGIS.
cheat-sheet for fiona and rasterio - Cheatsheet for using python libraries of fiona, rasterio, manipulating geospatial data.
miller - command-line based; very powerful and advanced; specifically for parsing CSV files.
GDAL cheatsheet - GDAL is a geospatial library at the core of many geospatial applications; data conversion; reprojection; analysis, and more. Cheatsheet for using some of its command-line based tools.
d3 - extremely powerful javascript library for dataviz and maps
observable HQ - a sandbox for experimenting with javascript and D3
Sites/Articles mentioned in talk:
Most famous set in every US state
data sources: Guide to Cleveland Data sources - A list of places to get available open civic data for the Cleveland area
If you want to start with the command line: https://github.com/jlevy/the-art-of-command-line
Highly recommended Books: Interactive Data Visualization for the Web: An Introduction to Designing with D3 (2nd Edition) - Scott Murray - clearly written with examples; good not just for D3 as a refresher or extremely concise overview of html, css, and javascript.
GIS Cartography - Gretchen Peterson Great design influence for making print and web-maps.
cat photo by Walid Mahfoudh
Mar 11, 2018 - Recently
What I’ve been up to (outside of my work):
I used to spend a lot of time listening, finding, and buying new music. I don’t nearly listen to as much as I used to; my priorities in my free time have changed. Tracking down or knowing that there’s a great song or album to be found just doesn’t give me as much excitement it once had.
However, these songs were my favorite ones to listen to in 2017 and will remind me of that year for the rest of my life (alphabetical order):
Broken Social Scene - Halfway Home
Broken Social Scene - Anthems for a Seventeen Year Old Girl
Dday One - Contact
Dirty Projectors - Little Bubble
Dolly Spartans - I Hear the Dead
Doves - Rise
Gomez - Options
Noname - Diddy Bop (feat. Raury & Cam O’bi)
Orbital - Belfast
pronoun - a million other things
Sammus - 1080p
Talking Heads - Once in a Lifetime
The Go-Betweens - Love Goes On!
The War On Drugs - Pain
Ultimate Painting - Song for Brian Jones
Some of the favorite albums that I listened to for the first time in 2018: AndyFellaz - BeatBop Street; Kendrick Lamar - DAMN; The Go-Betweens - 16 Lovers Lane; broken social scene - you forgot it in people.
I’ve been stewing on the rest of this post for almost a year now. Deleting portions. I’ve scrapped multiple versions of it.
2017 had been the most successful year for me, professionally. Personally, it’s been one of the hardest, battling anxiety and to a lesser extent, depression. I know I’m pretty fortunate; my struggles are a lot less burdensome than others and I have a lot of privilege.
Articulating my thoughts into sustained, multiple paragraphs in a coherent fashion that is also grammatically correct and well-polished for general audiences is relatively difficult for me.
I’ve been spending less time on twitter and trying to spend the time that I’ve devoted to that on reading books or actually reading articles that I’ve saved (liked/favorited) on twitter. I made a conscious effort to go through my twitter likes a couple weeks ago: I had 4200; now down to ~3,500 (~3,200 now). Found some articles worth reading and it was a nice window in my internet consumption over the years. It also reminded me how much link rot is prevalent.
Reminded me that I spend less time in the open source geospatial community because my full-time job in general web development nowadays (primarily wordpress and CSS language/CMS-wise; making sure that cpl.org is functional). In my experience, the opensource geo community was generally quite welcoming to new people, respectable in their behaviors at conferences and online, would work together, would sometimes prioritize (and corporate users would fund) developing documentation.
Reading these saved tweets also reminded that many of my peers, especially those I professionally admire, had unfinished projects and blog posts.
There’s a lot more to write, especially my experiences with open data and civic technology in the past couple years.